
Judge us by the companies we keep.




Swisscom migrates from on-premises security to Verimatrix’s Video Content Authority System (VCAS™) SaaS in the cloud.
Swisscom transited to the Verimatrix VCAS SaaS on AWS, leveraging the advantages of scaleable, cloud-based anti-piracy operations.
Crédit Agricole Payment Services aimed to enhance the security of their French payment app “Paiement Mobile.” They selected Verimatrix’s XTD to guard against threats.
Crédit Agricole successfully deployed Verimatrix Extended Threat Defense technologies to enhance the security of their mobile payment app.
Little Cinema Digital partnered with Verimatrix to secure pre-release content and deliver engaging virtual premieres using Streamkeeper Multi-DRM and Watermarking.
Verimatrix’s security technology allowed Little Cinema to stream highly-anticipated video content to a global audience, shaping the future of Hollywood.
TELUS initiated Project OPUS to transform Optik TV, simplifying content interaction. They chose Verimatrix Streamkeeper for robust security.
TELUS partnered with Verimatrix for hybrid cloud security, cost-effectiveness, and geo-diverse services.
Secure your Android, iOS and web apps with advanced obfuscation. Compatible with all browsers, JavaScript, frameworks, and libraries across hybrid environments.
Verimatrix supports Angular, EmberJS, Ionic, Meteor, NativeScript, Next.js, Node.js, Nuxt.js, React, React Native, Vue, Webpack and HTML 5, to name a few!


Apply military-grade, layered security to your mobile apps to secure blind spots and harden apps.

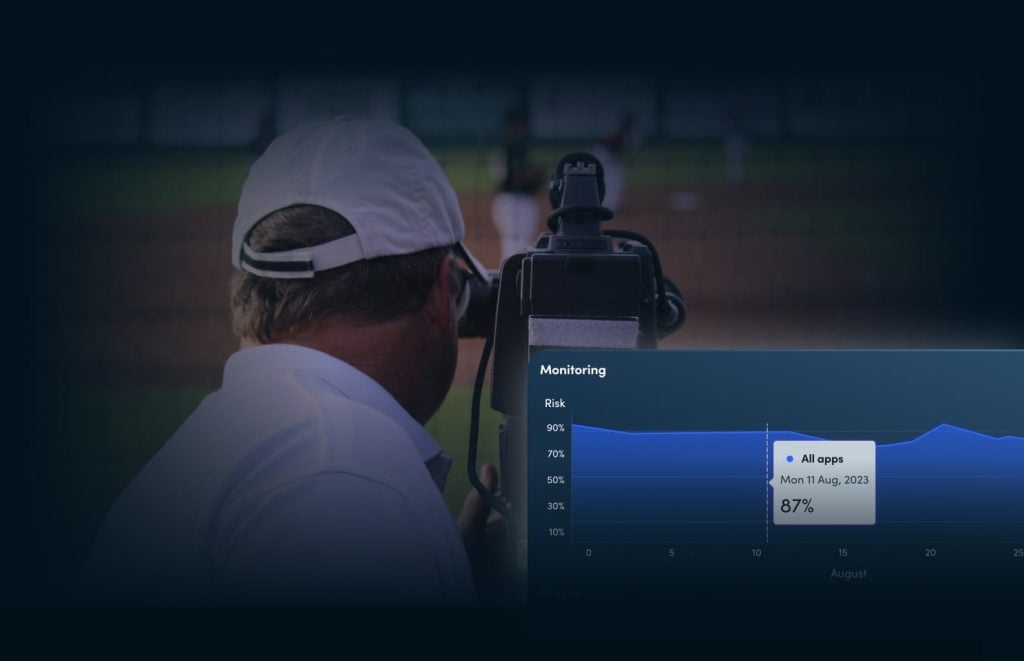
Get a complete overview of the protection and risk level of your infrastructure with XTD’s SIEM integratable detect and respond dashboard.
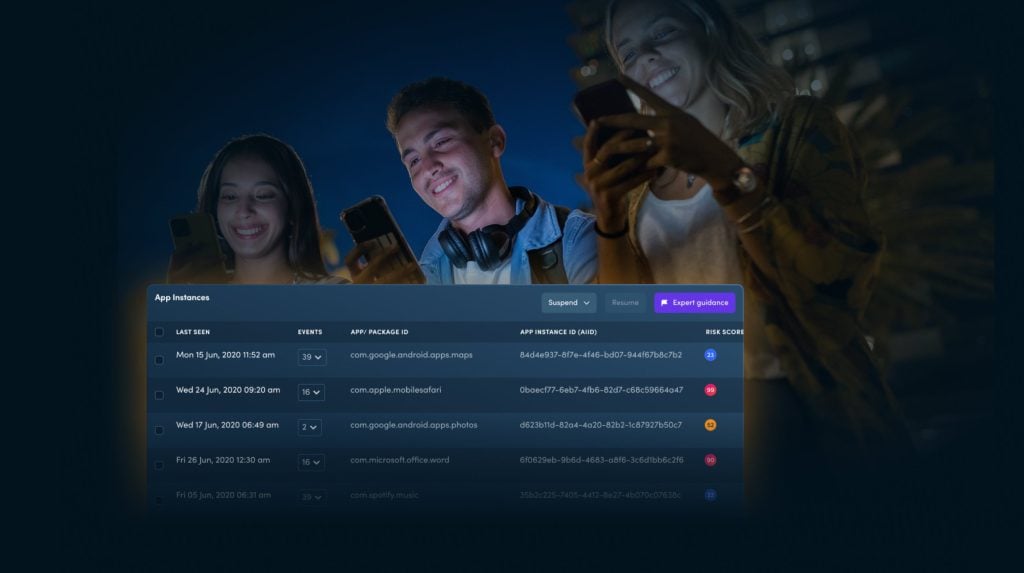
When risks are detected, you’re in full control over how you respond to them.
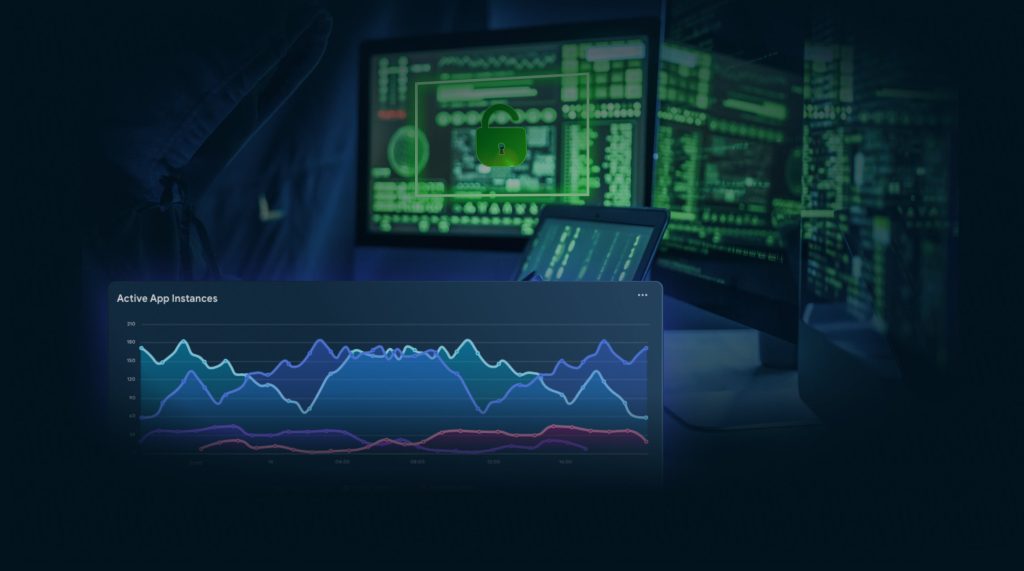
Leveraging powerful AI/ML algorithms, helps security teams predict potential threats in the future.
Streamkeeper combines digital content security with app protection to defend against piracy.
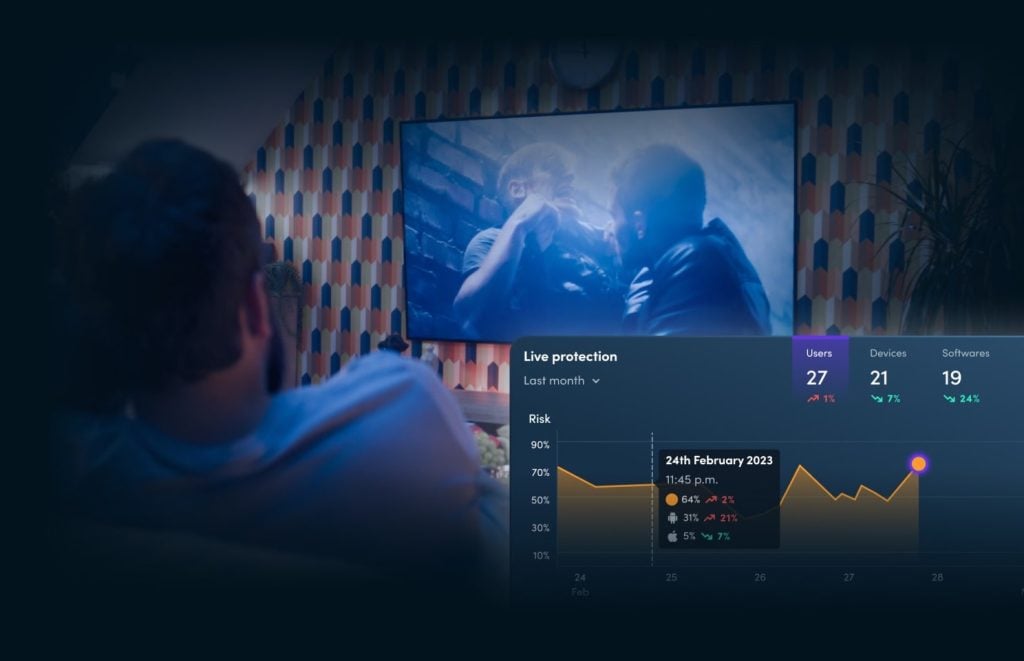
Protect your revenue, subscribers and reputation with next-generation piracy prevention, app protection, risk monitoring and automated countermeasures.
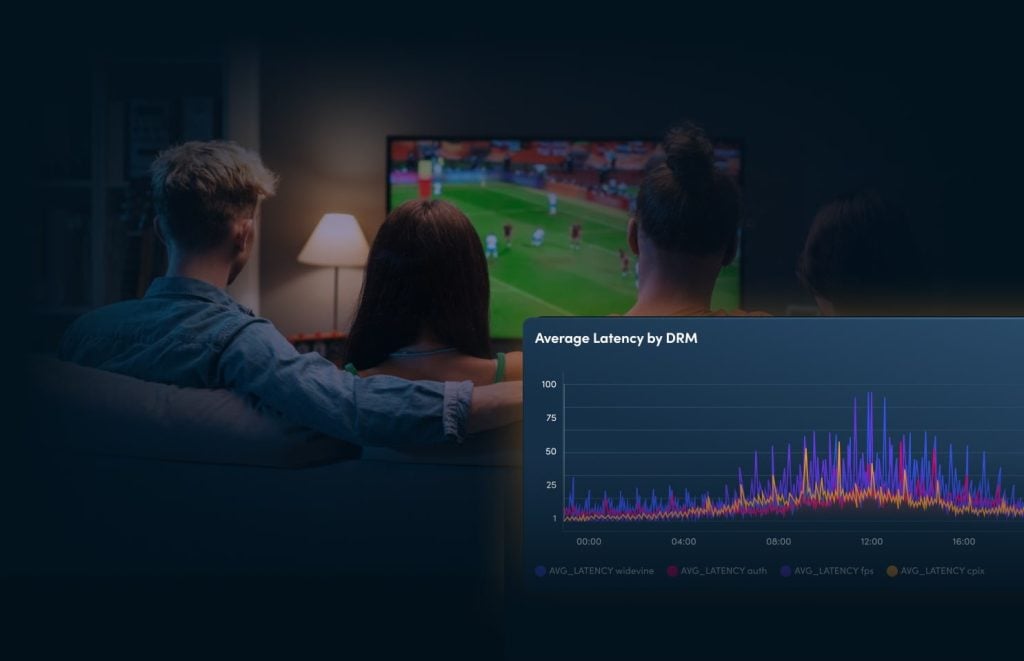
Watermarking rapidly identifies the source of distribution, ensuring traceability of content leaks from any device.
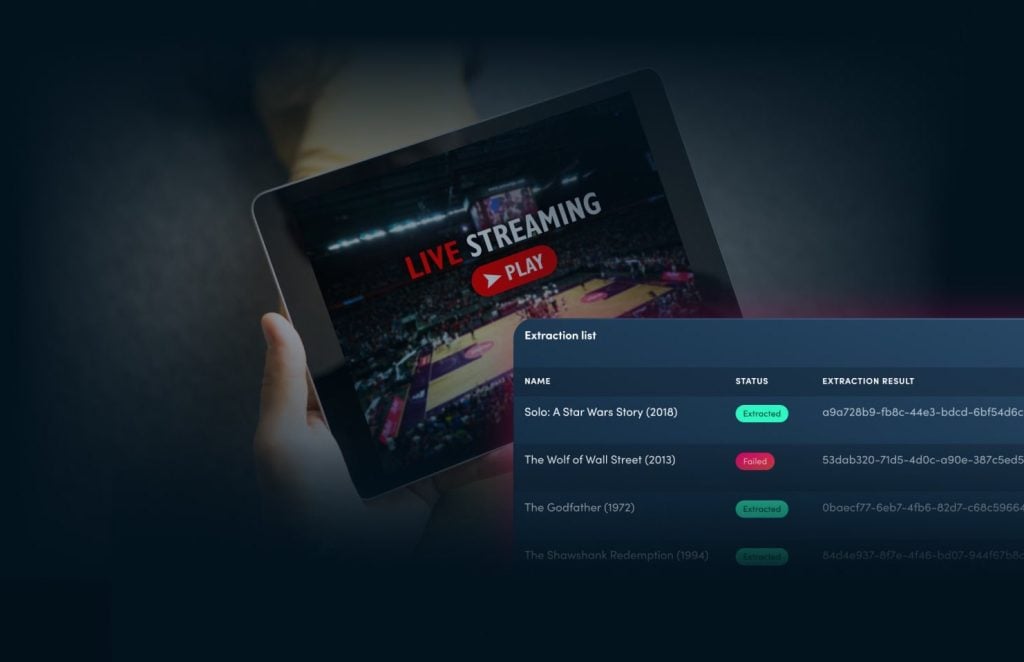
Secure content in 1-click, it doesn’t get easier than Multi-DRM.
Streamkeeper Suite combines the capabilities of Multi-DRM, Watermarking and Counterspy to safeguard your entire content distribution ecosystem.

VCAS scales as you grow and provides revenue security across a wide range of networks and device types.
Verimatrix has helped power the modern connected world with security made for people for over 29 years. We protect digital content, applications, and devices with intuitive, people-centered and frictionless security.
Cybersecurity
The developer’s guide to securing, detecting & responding to threats to mobile apps
Uncover each of the OWASP Mobile Top 10 vulnerabilities, with valuable insights and actionable strategies to bolster your app’s defenses.

Anti-piracy
Get a better understanding of Verimatrix Counterspy, a revolutionary anti-piracy technology that protects OTT & video streaming apps.

VMX
labs

Learn how Verimatrix's solutions deliver a one-two punch against piracy.
Get the latest insights delivered straight to your inbox.
Our world-class security expertise and deep industry experience protects the people, processes and technologies that drive modern enterprise.

“With multiple media apps to support deployed across millions of devices, we look forward to the benefits that Verimatrix’s enhanced security solutions will provide to our business.”

Video and Hubs Director at izzi
“By integrating Verimatrix Streamkeeper with our VOS360 cloud platform, we are transforming how operators stream video.”

Senior vice president, video products and corporate development at Harmonic
“Fastway’s Android set-top boxes are secured by Verimatrix, providing peace of mind.”

CMD of Jujhar Group
“We selected Verimatrix due to its comprehensive approach to IP protection and its unique threat monitoring capabilities for mobile apps.”

Chief Operations Officer at Jarir Bookstore
“Our payment solutions depend upon Verimatrix cybersecurity to help us continuously monitor the security posture of our mobile apps.”

CEO at Tidypay
“Working with retailers and quick commerce players, we know security is an important topic for our business. We’re pleased to work with Verimatrix XTD technologies.”

Co-Founder and CEO at Nomitri
“Verimatrix is a great company to work with and the integration of Streamkeeper Multi-DRM and Watermarking increases the confidence in our platform, provides convenient speed to market with ‘one-click security’ capabilities.”

Founder at Little Cinema
“We couldn’t be more excited. By integrating Verimatrix Streamkeeper’s layered approach to security, we have an incredibly powerful and future-proof system that will serve our customers well for years to come.”

Director of Content & Consumer DevOps at TELUS
“The combination of Verimatrix’s content protection and anti-piracy solutions with Agama’s End-to-End Video Observability helpx service providers achieve exceptional quality and operational efficiency.”

Director of Product and Engineering at Agama
“Verimatrix XTD offers us state-of-the-art technology to cater to our evolving security needs.”

Managing Director at GTPL Hathway Limited
“Verimatrix not only understands the unique needs of the media & entertainment space, but it is also a heavily trusted expert in both app protection and mobile threat defense – the perfect mix for our business.”

CTO at United Cloud
“Verimatrix Streamkeeper Multi-DRM with Scalstrm’s Origin and CDN platforms is a game-changer for operators and a testament to our commitment to delivering cutting-edge streaming solutions.”

Sales Director at Scalstrm
“By adding Verimatrix anti-piracy technologies, we’re creating an even more formidable security posture for our company, our content and our customers.”

Chief Marketing Officer at Megacable
“Having relied upon the on-premises VCAS solution for more than eight years, Swisscom is confident in its move to SaaS-based content security through Verimatrix to best serve our customers.”

Head of the technology group at Swisscom TV & Smart Products
Verimatrix helps customers confidently deliver experiences people love at the speed people live.








3 Security Imperatives for Vehicle App Manufacturers in 2024
Vehicle app manufacturers in 2024 face critical security challenges, including the OWASP Mobile Top 10 vulnerabilities. Read here for key strategies.